
Scraper Crawler V3
29 个评分
)
概述
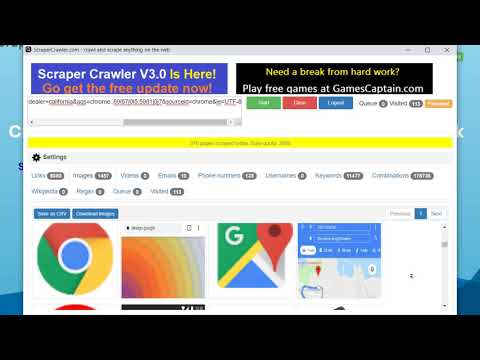
Crawl to any search results and scrape texts, links, images, keywords, emails & videos
Scraper Crawler V3.0 is here! Can scrape thousands of Emails, phone numbers, links, SEO keywords, images and videos - and in the new version - also RegExps, Wikipedia pages, Instagram users, keywords combinations - all in one click and very faster than ever. Free features include *all scraping options* for 100 websites a day. Please support us with a $1 donation or buy the extended license to get unlimited scraping. How to use it? - You go on a website, or a search engine results page - Click the scraper button - Click "start" - In the "Settings" tab, you can choose *what* to scrape, how deep to crawl, waiting times (you need waiting time if the site your crawl to has limitations!), and if to crawl into the original domain only or to continue crawling to the whole web. - Scrape SEO keyword sentences - Scrape phone numbers, skype accounts, wikipedia content, instagram/twitter accounts, and much more! - Target your competitors SEO design - Download all videos, images directly - Upload a list of URLs to scrape - Save scraped images to local folder. The scraper is looking for pagination pages as well, so if for instance you went on a search engine results page, the scraper will try to click "next" for you. NOTE! Faked accounts or accounts without an Email will get deleted. Please report any bugs to desk12131415@gmail.com
2.2 星(5 星制)29 个评分
Google 不会核实评价。 详细了解结果和评价。
详情
- 版本3.6
- 上次更新日期2020年3月17日
- 提供方Open Source Dev
- 大小174KiB
- 语言English
- 开发者
电子邮件通知
desk12131415@gmail.com - 非交易者该开发者尚未将自己标识为交易者。欧盟地区消费者须知:消费者权利可能不适用于您与该开发者达成的合约。