
Image Reader (OCR)
۲۳ ردهبندی
)
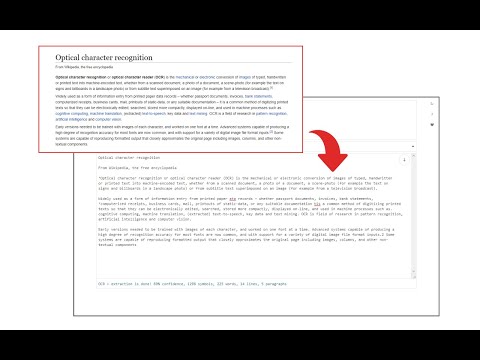
نمای کلی
Easily get words out of an image with OCR engine!
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
۳٫۷ از ۵۲۳ ردهبندی
Google مرورها را درستیسنجی نمیکند. درباره نتایج و مرورها بیشتر بدانید.
جزئیات
- نسخه0.1.7
- تاریخ بهروزرسانی۱۶ آذر ۱۴۰۲
- ارائهکنندهSevina
- اندازه7.51MiB
- زبانهاEnglish
- تولیدکننده
ایمیل
sevina.lucia@gmail.com - غیرتاجراین توسعهدهنده خودش را بهعنوان فروشنده معرفی نکرده است. اگر مصرفکنندهای در اتحادیه اروپا هستید لطفاً توجه داشته باشید که حقوق مصرفکننده برای قراردادهای میان شما و این توسعهدهنده اعمال نمیشود.
حریم خصوصی
این توسعهدهنده اعلام میکند که دادههای شما
- خارج از موارد استفاده تأییدشده، به اشخاص ثالث فروخته نمیشود
- برای اهداف نامرتبط با عملکرد اصلی مورد استفاده یا منتقل نمیشود
- برای تعیین اعتبارمندی یا برای اهداف وامدهی استفاده یا منتقل نمیشود
پشتیبانی
برای دریافت راهنمایی درباره سؤالها، پیشنهادها، یا مشکلات، از سایت پشتیبانی توسعهدهنده بازدید کنید