
Image Reader (OCR)
23 个评分
)
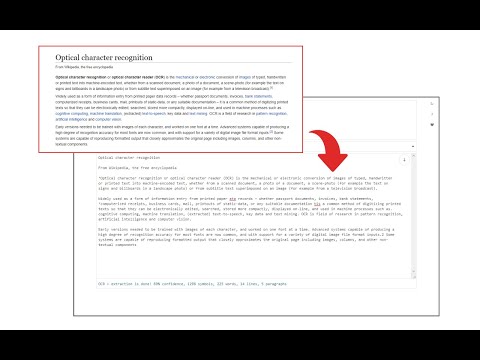
概述
Easily get words out of an image with OCR engine!
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
3.7 星(5 星制)23 个评分
Google 不会核实评价。 详细了解结果和评价。

Knowing Horse2024年3月3日
对英文识别效果挺好。对中文支持不太理想,会有错别字。还请优化中文识别。
详情
- 版本0.1.7
- 上次更新日期2023年12月7日
- 提供方Sevina
- 大小7.51MiB
- 语言English
- 开发者
电子邮件通知
sevina.lucia@gmail.com - 非交易者该开发者尚未将自己标识为交易者。欧盟地区消费者须知:消费者权利可能不适用于您与该开发者达成的合约。
隐私权
支持
若有任何疑问、建议或问题,请访问开发者的支持网站