


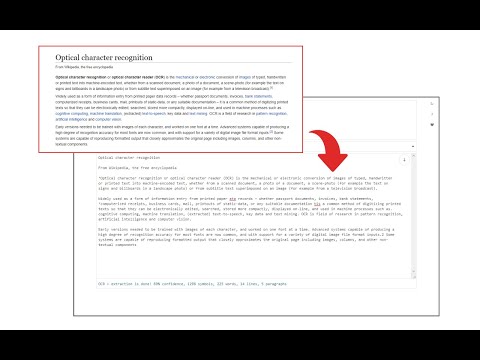






Overview
Easily get words out of an image with OCR engine!
Image Reader (OCR) extension helps you easily get words out of any image. It uses an open-source OCR library called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR language. Default OCR language is set to English. Note: this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. Language data packs are very large and cannot be included in the addon package. To report bugs, please fill the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
3.7 out of 526 ratings
Google doesn't verify reviews. Learn more about results and reviews.
Details
- Version0.1.8
- UpdatedDecember 30, 2024
- Offered bySevina
- Size7.53MiB
- LanguagesEnglish
- Developer
Email
sevina.lucia@gmail.com - Non-traderThis developer has not identified itself as a trader. For consumers in the European Union, please note that consumer rights do not apply to contracts between you and this developer.
Privacy
This developer declares that your data is
- Not being sold to third parties, outside of the approved use cases
- Not being used or transferred for purposes that are unrelated to the item's core functionality
- Not being used or transferred to determine creditworthiness or for lending purposes
Support
For help with questions, suggestions, or problems, visit the developer's support site